
官方针对1080Ti 2080 2080Ti进行了对比测试,测试中还对比了未发布支持光线追踪的Vray版本、以及双卡NVLink测试结果,非常具有参考价值。不过NVLink就有点坑并不是我们想象的渲染提速或翻倍,反而渲染会变慢,双卡互联仅仅可以渲染更大的场景。另外新版V-Ray Next for 3ds Max Update 1已经发布本站也有官方宣传视频,视频中有CPU和GPU渲染对比测试。近年来Vray一直在加大GPU渲染的研发,草图联盟预计用不了多长时间Vray的GPU渲染速度就会赶上Enscape。
以下测试内容来自Vray官方,本站进行了整理翻译,转载请注明出自草图联盟。
这是我们的RTX光线追踪帖子的后续博客文章。在我们撰写博文时,GeForce RTX显卡刚刚公布,在这些显卡尚未正式发布之前我们无法分享任何特定的基准测试结果。
现在显卡已经发布,我们可以分享实测结果。我们只展示GeForce RTX 2080和GeForce RTX 2080 Ti卡以及上一代GeForce GTX 1080 Ti的测试结果,因为这些显卡比较重要。
这些显卡在所有最新版本的V-Ray GPU运行都没有任何问题,尽管还没有利用新的RT核心 我们正在研究RT光线追踪问题,您可以在下面阅读我们的测试。
对于这些基准测试,我们使用了以下场景(一些Evermotion场景是从原始场景修改过的):

CUDA表现
对于第一组测试,我们使用了常规CUDA版本的V-Ray GPU Next,这个版本还不支持RT Cores。我们测试了RTX 2080和RTX 2080 Ti卡的纯CUDA性能,并将它们与GeForce GTX 1080 Ti进行了对比,后者目前非常适合GPU渲染。

从这些测试中可以看出,RTX 2080和RTX 2080 Ti通常比上一代GTX 1080 Ti更快。仅比较Ti卡时,结果显示,与之前的Pascal架构显卡对比,图灵架构显卡渲染速度平均提高1.52倍。这是在V-Ray Next正式版中的测试结果。
RT Core性能
虽然我们还没有发布支持RT Core的官方版本,但我们已经与英伟达合作了一段时间,为新显卡准备V-Ray GPU。目前,我们尚未发布的V-Ray GPU中的RT核心是基于OptiX,而支持RT核心的OptiX官方还没有发布,因此支持RT Core的V-Ray GPU发行版的开发还需要一段时间。我们仍然可以使用现有的版本进行一些性能测试,最终的发行版本性能可能会有所提高。
下面的测试了V-Ray GPU支持RT Core的内部测试版。我们仍然有许多改进可以进一步提高性能。
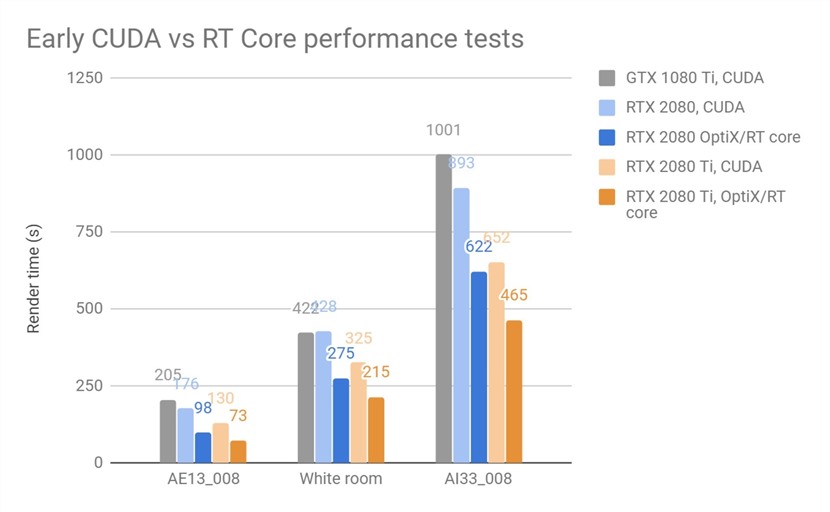
对于这三个场景,与纯CUDA版本相比,RT Cores分别提高1.78x,1.53x和1.47x的加速。随着未来几个月官方正式版发布,我们预计性能会更好。
DXR 性能
对于这组测试,我们使用了我们首次在Siggraph 2018上发布的Project Lavina实时光线追踪引擎。它基于DirectX 12的DXR光线追踪扩展,并从头开始实时编写光线追踪性能。该引擎完全基于光线追踪,包括阴影,反射,折射和GI的多次反弹,并使用降噪通道来平滑结果。根本没有涉及光栅化,RT Core被大量使用。GTX 1080 Ti等老一代GPU不支持DXR,所以现在我们只能比较两款可用的GeForce RTX卡。
对于HD分辨率,DXR测试的结果以每秒帧数为单位,因此帧数越高性能越好:

从这些测试结果来看,RTX 2080 Ti显卡的性能比RTX 2080卡平均提高了1.35倍。
NVLink性能
除了RT Core之外,新的RTX卡还支持NVLink,这使得V-Ray GPU能够共享多块显卡显存。这对渲染速度有一些影响 - 在这个基准测试中,我们的目标是测试它。为了启用NVLink,需要使用特殊的NVLink连接器(也称为NVLink Bridge)连接这些卡。GeForce RTX卡有两种类型的连接器:三槽宽和四槽宽,具体取决于卡的物理距离。Quadro RTX卡的NVLink网桥分别为两插槽和三插槽。

适用于GeForce RTX卡的三插槽和四插槽NVLink连接器:

两块RTX 2080 Ti显卡与四插槽NVLink连接器连接:
要想NVLink在Windows上运行,GeForce RTX卡必须从NVIDIA控制面板进入SLI模式(这不是Quadro RTX卡所必需的,在Linux上也不需要,并且不建议用于较旧的GPU)。如果禁用SLI模式,NVLink将不会启用。这意味着主板必须支持SLI,否则您将无法将NVLink与GeForce卡配合使用。另外值得注意的是,在SLI组中,只有连接到主GPU的监视器才能工作。此外,如果两个GeForce GPU在SLI模式下链接,其中至少有一个必须连接显示器(或虚拟插头),以便Windows可以识别它们(这不是Quadro RTX卡所必需的,在Linux上也不需要) 。

启用SLI模式的NVIDIA控制面板的屏幕截图(Windows上带有GeForce RTX卡的NVLink需要SLI模式):
RTX 2080和RTX 2080 Ti显卡之间的NVLink速度也不同,因此我们估计使用NVLink会得到不同的性能测试结果。
在下面的测试中,我们使用SLI模式和非SLI模式的显卡渲染了几个场景,以了解NVLink对性能影响。我们使用常规CUDA版本的V-Ray GPU进行这些测试。在某些情况下,由于每个GPU上的显存分别有限,场景无法在非SLI模式下渲染。
请注意,使用NVLink,GPU渲染的可用显存不会完全加倍 出于性能原因,V-Ray GPU需要在每个GPU上复制一些数据,并且需要在每个GPU上保留一些显存作为在渲染期间进行计算的寄存器。尽管如此,使用NVLink可以让我们渲染比使用单块显卡更大的场景。
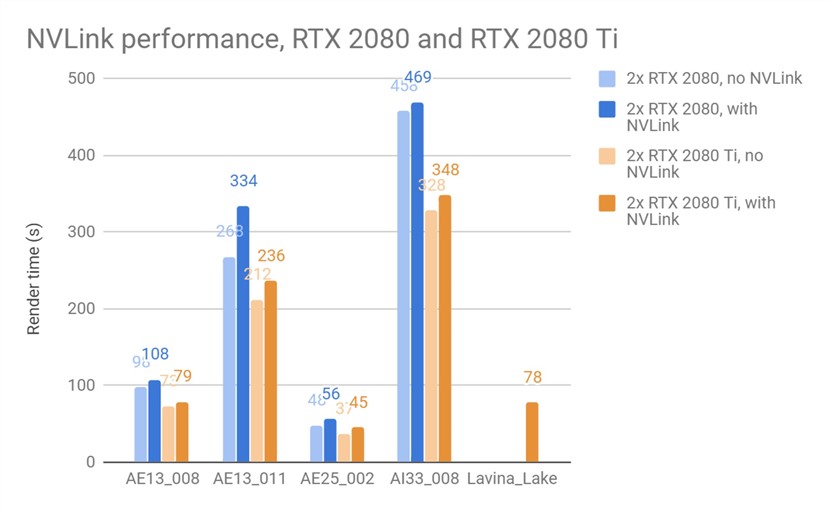
最后一个场景Lake Lavina只能使用RTX 2080 Ti卡在NVLink模式下渲染,并且由于GPU显存不足而无法在其他测试场景中渲染。可以看出,与单独在GPU上渲染相比,NVLink确实对性能产生了一定影响,但它允许渲染更大的场景。在许多情况下,变慢只是百分之几。在未来微调在两张卡之间分配数据的方式可以提供更好的性能。
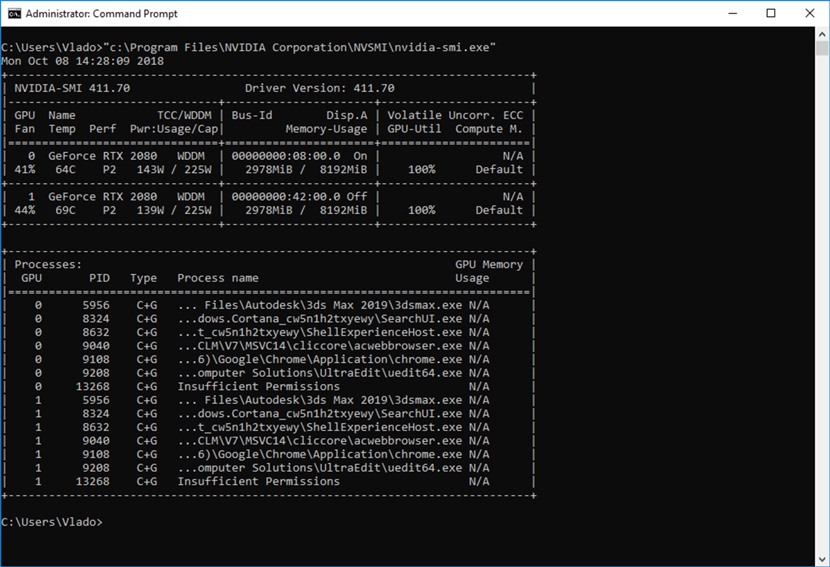
重要提示:看起来NVIDIA目前提供的常规GPU内存报告API(在撰写本文时)在SLI模式下无法正常工作。这意味着像GPUz,MSI Afterburner,nvidia - smi 等程序可能无法显示每个GPU的准确显存使用情况。知道了这一点,我们修改了V-Ray帧缓冲区中显示的内存统计信息,以便您可以监控实际GPU内存使用情况。我们预计NVIDIA将来会纠正这些问题。

新版本的V-Ray GPU显示GPU显存准确的显存编号。

启用SLI时,Nvidia-smi工具在两张卡上显示不正确的显存使用率。
与其他系统工具相比,V-Ray GPU在V-Ray帧缓冲区中报告的内存使用准确。请注意,V-Ray GPU显示剩余的GPU显存而不是已用显存。
结论
今天,新的RTX 2080显卡提供了比以前使用V-Ray GPU的GTX 1080卡更好的性能,并且使用NVLink使可以渲染更大的场景,只牺牲很小的性能。RTX Core显卡中内置的新RT核和NVLink技术为未来带来了许多希望,但充分利用它们需要对软件进行更多优化和微调,我们希望在未来几个月内看到这些优化。
用户在本站下载的作品,只拥有该作品的使用权,著作权归草图联盟网所有,用户的下载行为不构成作品著作权的许可或者转让。未经书面授权,用户不得以任何形式发布、传播、复制、改编、汇编、转售该作品,不得实施任何侵犯作品著作权的行为。






